Hash算法以及为什么重写equals一定要重写hashcode
一个优秀的哈希算法有什么特点?
- 快速性,速度快,效率高
- 不可逆性
- 敏感性
- 低碰撞性
进行取舍,不同hash算法侧重点不同
java中的Hash算法
HashMap,侧重点是速度
Object.hashCode 直接获取内存地址
Integer.hashCode 直接返回的intValue
String.hashCode 根据字符串内容生成hashCode,字符串内容一样则hashCode也相同
其他场景中的Hash算法
MD4,MD5
sha(sha-1,sha-24,sha-256,sha-384,sha-512) sha后面的数字代表长度

解决办法:再散列函数法,链地址法(就是hashmap用的那个方法来解决地址冲突的)
哈希算法的用途
- 哈希查找,哈希表
文件校验/文件签名
HashMap
加解密,MD5,SHA
git
比特币,区块链
手写HashMap及源码分析
HashMap 初始容量是16
加载因子DEFAULT_LOAD_FACTOR是0.75 ,threshold阈值是容量乘以0.75 ,也就是12 ,满12个就要扩容

modCount是修改次数
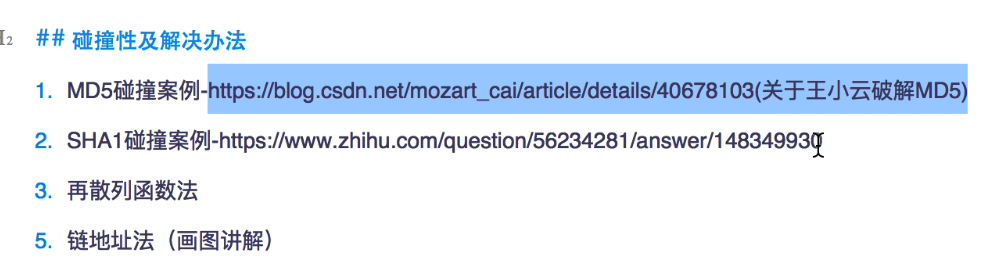
hashmap的hash方法也是调用的Object的hashCode方法
HashMap能够将键设为null,也可以将值设为null。Hashtable不能将键和值设为null,否则运行时会报空指针异常错误;
为什么重写equals的时候一定要重写hashcode方法? 见文章下面
根据这个hashcode来生成这个元素所在数组的位置(索引) ,方式是hashcode和长度-1做一个按位与操作,和h%length的结果是一样的,但是这种方式效率更高

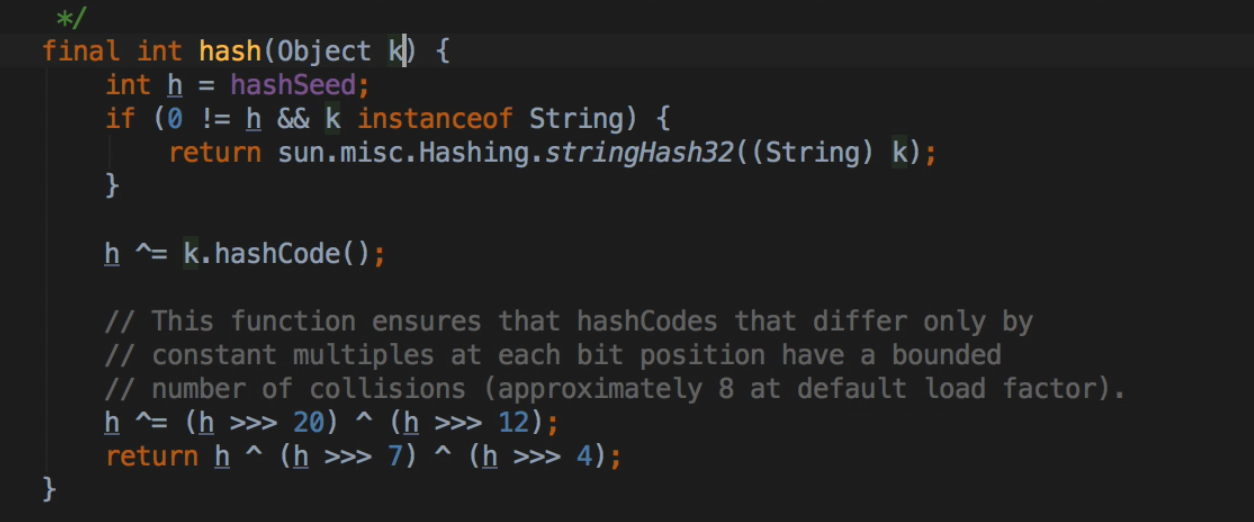
如果size大于阈值,就会扩容,扩的是数组长度,扩容到目前大小的2倍 ,扩容后会重新hash,也会算出新的数组下标
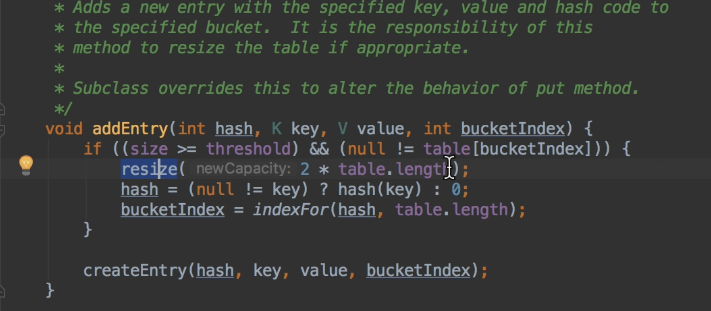
get,根据key计算hash,找到对应的数组上的链表,然后循环遍历key相等的取值
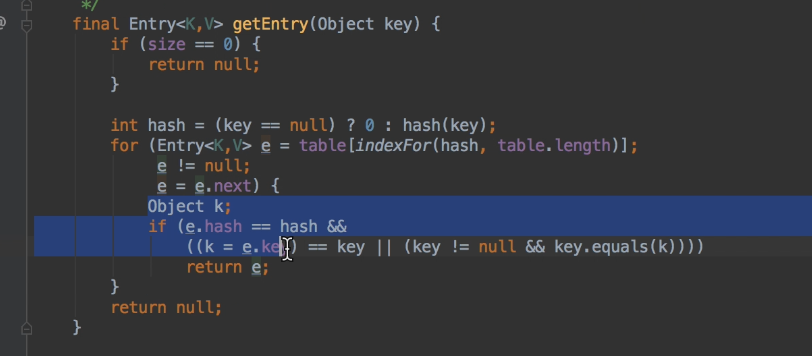
当key为null的时候,存在数组的第一个位置 (相当于写死了)
线程不安全
在迭代过程中修改hashmap会报错
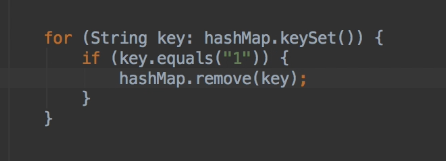
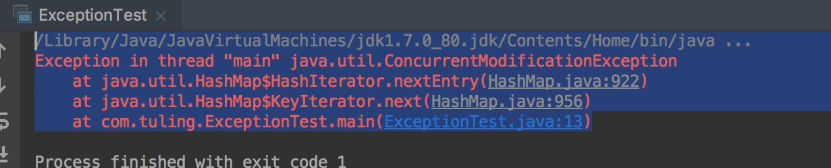
报错信息
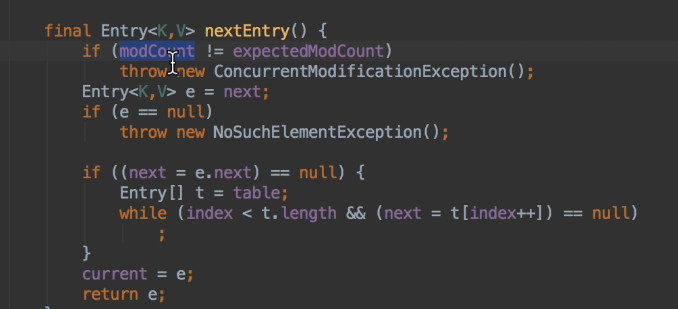
修改次数modCount在put,remove,add的时候会更新 +1,
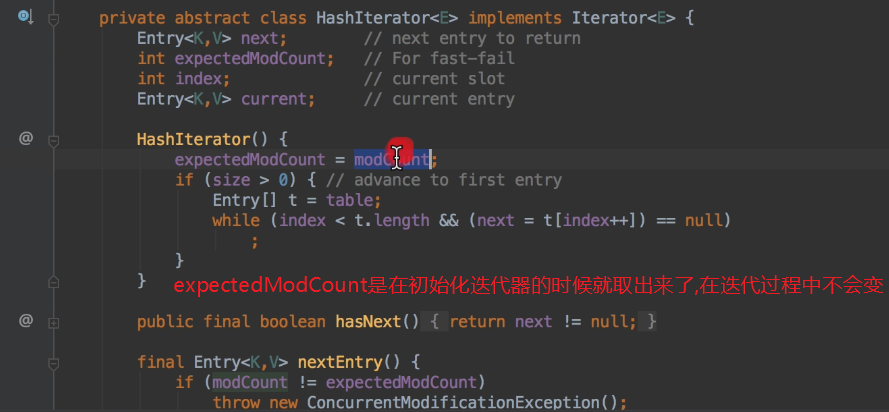
expectedModeCound在迭代的时候不会变,但是modCount在迭代时候被修改了,所以报错了
这样的情况叫做fail-fast,这么做是为了保证一个线程在遍历,一个线程在修改,防止出现多线程的问题,例如脏读或者幻读
作者是知道这个问题的,因为hashmap并不保证线程安全,所以它尽快的将错误抛了出来
resize的时候会出现死循环
https://blog.csdn.net/zhuqiuhui/article/details/51849692 头插法导致的
为什么要用2的次方数作为数组大小
1 新老索引尽可能保持一致,大大减少了之前已经散列良好的老数组的数据位置重新调换
2 低位全是1,有更好的散列性
为什么重写equals一定要重写hashcode?
大家都知道,equals和hashcode是java.lang.Object类的两个重要的方法,在实际应用中常常需要重写这两个方法,但至于为什么重写这两个方法很多人都搞不明白,以下是我的一些个人理解
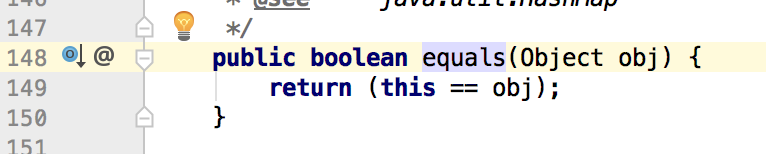
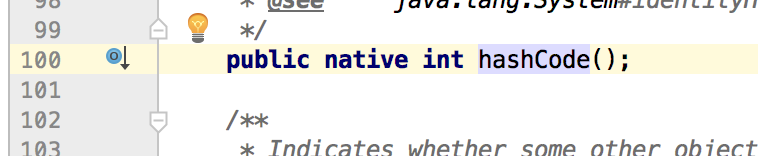
这是Object类关于这两个方法的源码,可以看出,Object类默认的equals比较规则就是比较两个对象的内存地址。而hashcode是本地方法,java的内存是安全的,因此无法根据散列码得到对象的内存地址,但实际上,hashcode是根据对象的内存地址经哈希算法得来的。
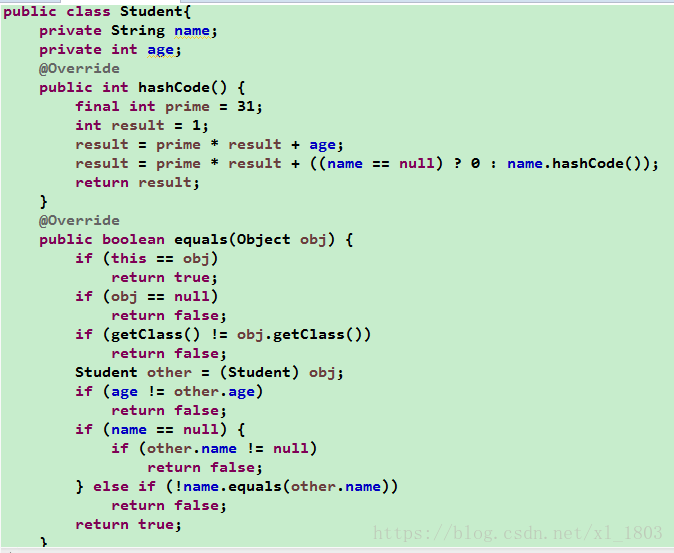
上图展示了Student类的重写后的equals方法和hashcode方法
现在有两个Student对象:
Student s1=new Student("小明",18);
Student s2=new Student("小明",18);
此时s1.equals(s2)一定返回true
假如只重写equals而不重写hashcode,那么Student类的hashcode方法就是Object默认的hashcode方法,由于默认的hashcode方法是根据对象的内存地址经哈希算法得来的,显然此时s1!=s2,故两者的hashcode不一定相等。
然而重写了equals,且s1.equals(s2)返回true,根据hashcode的规则,两个对象相等其哈希值一定相等,所以矛盾就产生了,因此重写equals一定要重写hashcode,而且从Student类重写后的hashcode方法中可以看出,重写后返回的新的哈希值与Student的两个属性有关。
以下是关于hashcode的一些规定:
两个对象相等,hashcode一定相等
两个对象不等,hashcode不一定不等
hashcode相等,两个对象不一定相等
hashcode不等,两个对象一定不等
不重写hash方法带来什么问题?
假如你的这个对象要放入HashMap,HashSet,HashTalbe等容器时:
进行key比较,put的时候都要调用hashcode方法,如果2个对象相等(按照你的equasl逻辑来说相等),但是hashcode没重写导致不相等,那么假如你put了,其实只是想更新,但结果却放了2个对象进去。
重载hashCode()是为了对同一个key,能得到相同的HashCode,这样HashMap就可以定位到我们指定的key上。
This blog is under a CC BY-NC-SA 3.0 Unported License
本文链接:http://hogwartsrico.github.io/2019/10/21/Hash-in-HashMap/